
SQL Query for number of records in all database tables
There have been several occasions in which I’ve been given SQL Server database backups to explore from various building automation systems or other building related software. An important first step in understanding what the structure of the database is to have a count of the number of records in the various tables.
Oftentimes, the databases that I’m examining are related to trended building automation system data. It’s likely that the raw data is stored in one of the tables, and that table is going to have many more records than any other.
There is not a way using SQL Server Management Studio (that I know of) to get the number of records across each table using the program interface directly.
For a single table, you can count the records using a query like:
SELECT COUNT(*) FROM [TableName]
All I would need is a list of tables, and then print these queries out
from something like a for loop. And in order to combine individual
queries, you can use the UNION SQL statement. Adding an alias for the
column headers, the final query we want looks like:
SELECT 'Table Name 1' as [Table Name], COUNT(*) as [Count] FROM [TableName1] UNION
SELECT 'Table Name 2' as [Table Name], COUNT(*) as [Count] FROM [TableName2] UNION
SELECT 'Table Name 3' as [Table Name], COUNT(*) as [Count] FROM [TableName3]
To get a list of all the tables, I used the script export feature of SQL Server Management Studio.
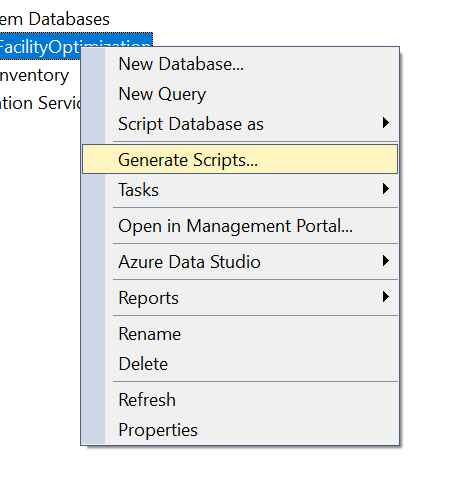
You can then click through the wizard and get your data into a file.
I then had a file that contained my table names, although it obviously is only a small portion of the file. See below for an example portion of the file.
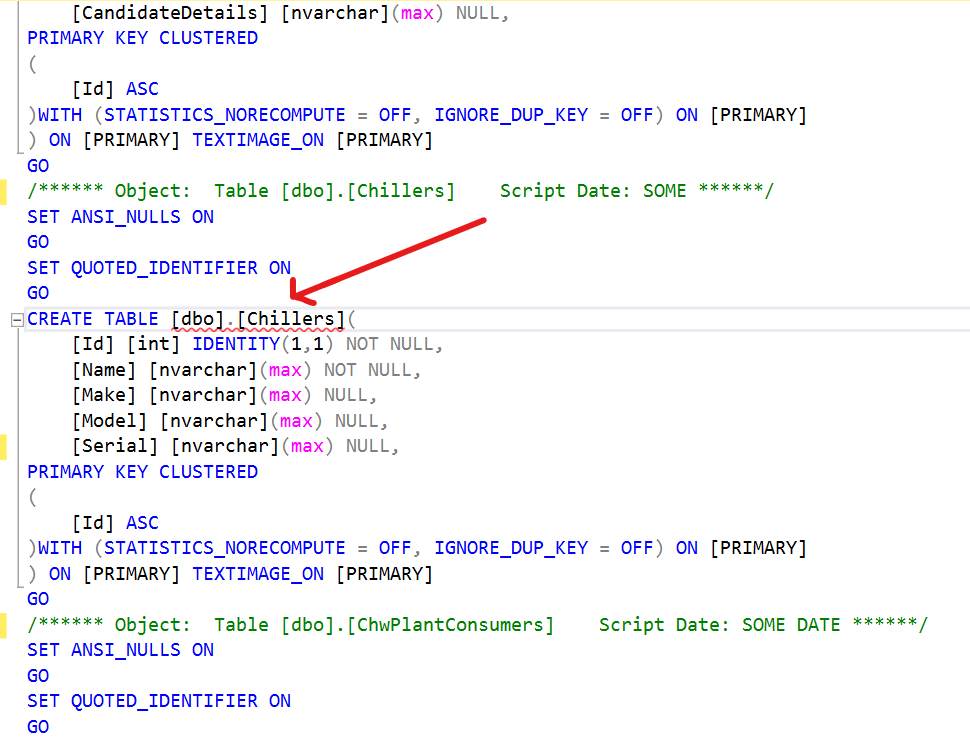
In situations like this, I’ll reach for trusty awk and pattern match
the table names out, along with printing my query.
The awk program looks something like:
#!/usr/bin/awk -E
# This function transforms the output from a SQL schema dump from
# SQL Server Management Studio into a sql query that counts the number
# of records for each table in the database.
BEGIN { FS=OFS="." }
/CREATE TABLE/ {
match($2, /\[.*\]/)
table_name = substr($2, RSTART + 1, RLENGTH - 2)
line[++n] = sprintf("SELECT '%s' as [Table Name], COUNT(*) as Count FROM [%s]", table_name, table_name)
}
END {
for (i = 1; i < n; i++) {
print line[i] " UNION"
}
print line[n]
}
Let me explain the important parts of this script.
#!/usr/bin/awk -E. This is called a shebang. It
allows me to call the script without explicitly using awk -f.
The generated script output has lines with our table names that look like:
CREATE TABLE [dbo].[Ahus](
I need the part [Ahus]. I don’t care about anything before the ‘.’ So I’m setting the field
separator (FS) to be the period.
I won’t explain everything about awk, but the lines
/CREATE TABLE/ {
match($2, /\[.*\]/)
table_name = substr($2, RSTART + 1, RLENGTH - 2)
line[++n] = sprintf("SELECT '%s' as [Table Name], COUNT(*) as Count FROM [%s]", table_name, table_name)
}
will run the code in the braces on lines that have CREATE TABLE in
them. It matches the second field for text in square brackets, extracts
the name portion without the brackets using substr, and then stores
the SQL query line that we want into an array called line.
Then once we’ve gone through all the lines (the END pattern), we can
print out each line with a UNION at the end, except the final line.
Then we can run this query and get the output we wanted.
awk -f table_record_count.awk ssms_output.sql
You can get a live copy of this script in my dotfiles repository here.